スクレイピングとはWebページに対して、DOM形式の情報を取得し、
ある特定の文字列をのみを抜き出したり、画像だけをダウンロードしたり、
情報の解析を行うことです。
今回はPythonでの実装方法に関してご紹介します!
なお、スクレイピングの過剰利用はアクセス先のサイトに対しての迷惑となったり違法となるケースがあるので気を付けてください。
https://topcourt-law.com/internet_security/scraping-illegal#i-10
https://qiita.com/n_oshiumi/items/b4efd1f40ec0a1b77376
◇ドライバーのダウンロード
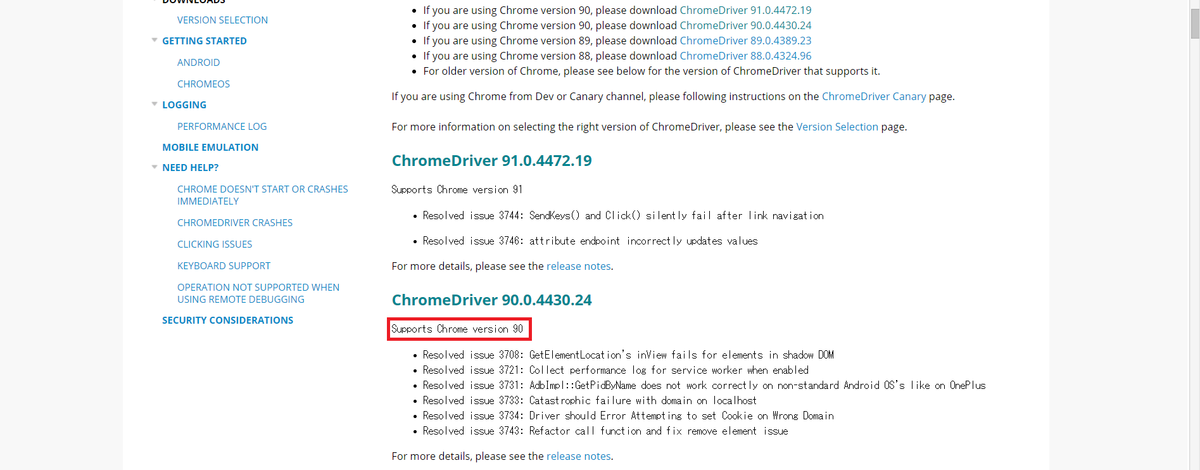
chromeを開いてurlに「chrome://version/」を入力し、ブラウザバージョンの確認。

ドライバーをダウンロード、確認したブラウザバージョンと照合してサポートされているものを選択します。
https://sites.google.com/a/chromium.org/chromedriver/downloads
ダウンロードしたドライバー(chromedriver.exe)はpyファイルと同じフォルダに格納、
もしくは環境変数のPATHにドライバーのパスを定義しておくのでも良い。
◇スクレイピングに向けてのライブラリをインストールしておく。
pip install selenium
pip install beautifulsoup4
anacondaを使用している場合は
conda install selenium
conda install beautifulsoup4
◇とりあえずスクレイピングしてみる。
googleの検索ページからgoogleロゴを取ってきてみる。
下記のような処理順で実装します。
①ローカルに保存ディレクトリを準備
②imgタグを検索し、該当したhtml形式の情報を取得
③imgタグのsrc属性にアクセスすることで画像へのパスを取得
④スライスでファイル名を取得
⑤ローカルへ転送
import os
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import selenium
import urllib.request as req
from bs4 import BeautifulSoup
TARGET_URL = "https://www.google.com/"
result_dir = './save'
if not os.path.exists(result_dir):
os.mkdir(result_dir)
options = Options()
options.add_argument('--headless')
article_browser = webdriver.Chrome(chrome_options=options)
article_browser.get(TARGET_URL)
html = article_browser.execute_script("return document.getElementsByTagName('img')[0].outerHTML")
soup = BeautifulSoup(html,"html.parser")
img = soup.find("img")["src"]
filename = img[img.rfind("/"):]
req.urlretrieve((TARGET_URL + soup.find("img")["src"]),result_dir + '/' +filename)
article_browser.quit()
下記のように撮れました!

よんで頂きありがとうございます。
良ければフォローお願いします!